Neural networks are increasingly successful for audio applications such as source separation, automatic speech recognition, and sequence embedding. Yet the phase spectra of audio signals are usually not modeled directly. It may be advantageous to jointly model phase and magnitude spectra, whether from Fourier-transformed or from raw waveforms.
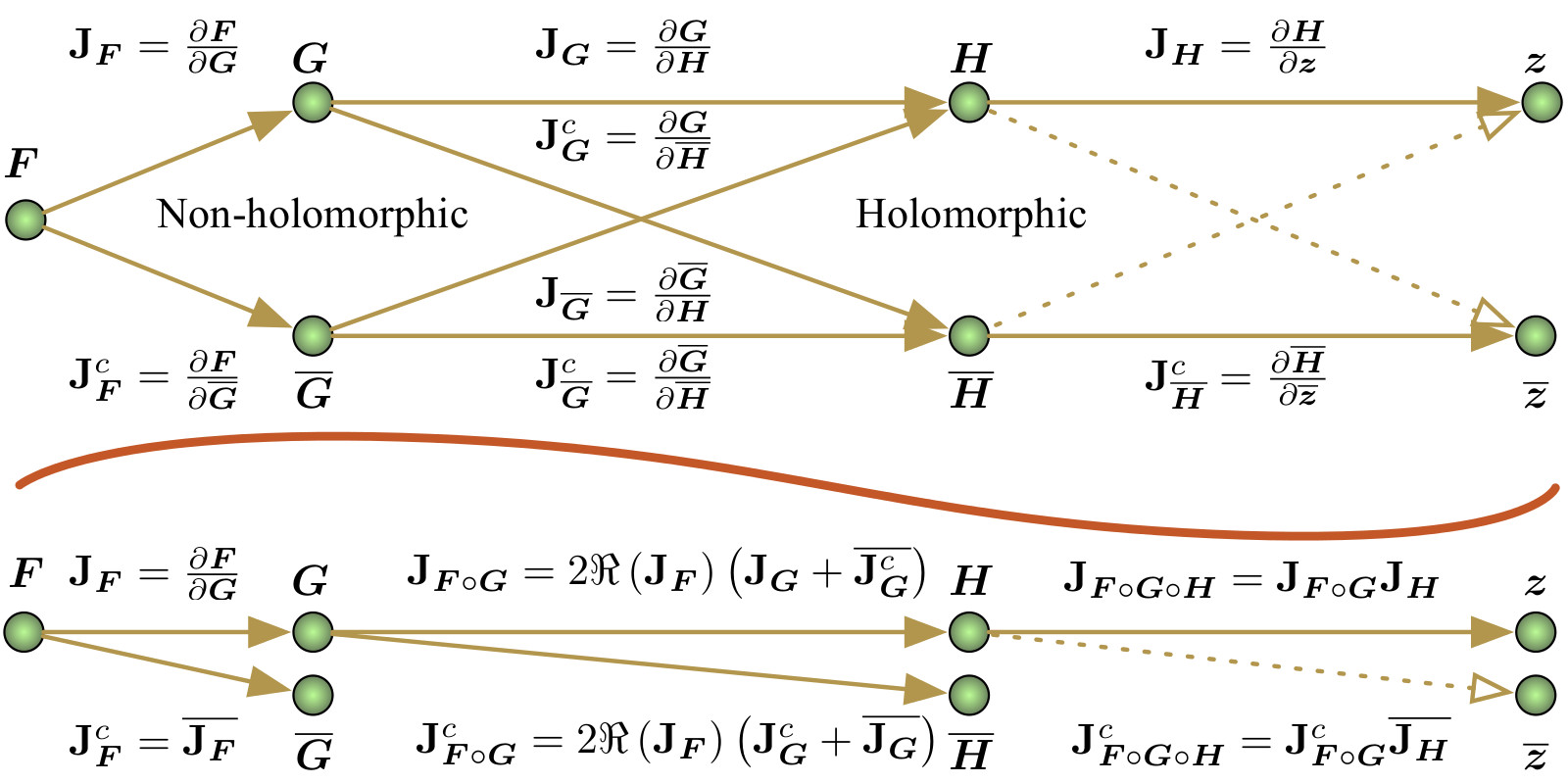
The project describes basic properties of complex-valued neural networks when applied to machine learning tasks on audio. We presented a poster on preliminary ideas at the 2015 Speech and Audio in the Northeast (SANE) workshop. A paper on the mathematical background for gradient-based learning can be found on arXiv (Sarroff, Shepardson, & Casey, 2015).
The doctoral dissertation titled “Complex Neural Networks for Audio” was successfully defended in May, 2018.
- Sarroff, A. M., Shepardson, V., & Casey, M. A. (2015). Learning representations using complex-valued nets. Link. Details